

科学研究


依托上海交通大学AI for Science科学数据开源开放平台,在上海市人工智能重大专项的支持下,变革性分子前沿科学中心朱峰副教授团队联合上海交通大学人工智能研究院AI for Science团队许岩岩副教授、金耀辉教授、杨小康教授等人,在人工智能化学有机合成领域(AI for Chemistry)取得重大原创突破。相关研究于2025年7月1日,以“Large language models to accelerate organic chemistry synthesis”为题在线发表在《Nature Machine Intelligence》,展现通用人工智能大模型赋能有机化学合成的巨大潜力。

自2023年初,人工智能研究院AI for Science团队开始构建白玉兰科学大模型,涵盖化学合成、蛋白质结构解析、流体力学、城市科学等基础与新兴学科。作为白玉兰科学大模型的成果之一,该研究首次实现化学大语言模型加速有机合成全流程。无需量子计算,仅依靠化学知识理解和推理能力,实现了在单步/多步逆合成、产率预测、选择性预测、反应优化等多个基准任务上,超越以往所有已知的最佳结果。建立了“Co-Chemist”人机协作的主动学习框架,在一项全新的、未曾报道的Suzuki-Miyaura交叉偶联反应中,仅用15次实验就成功找到了合适的配体和溶剂,实现了67%的分离产率,充分验证了其在加速真实化学发现中的巨大价值,解决了实验科学中反复试错的重大难题,为大型语言模型加速有机化学合成提供了新的研究范式和方法。
论文信息
Zhang, Y., Han, Y., Chen, S. et al. Large language models to accelerate organic chemistry synthesis. Nat Mach Intell 7, 1010–1022 (2025).
模型在线试用网址:
研究背景:
化学合成作为创造变革性分子的基础方法,对生命科学、材料和能源的各个领域产生了重大影响。尽管过去几十年化学仪器取得了长足进步,但面对浩瀚的反应空间和复杂的分子结构,化学家们仍需反复查阅文献、设计方案并进行湿实验验证。为了改变这一现状,传统的AI方法,如基于密度泛函理论(DFT)计算或贝叶斯优化的模型,虽然在特定任务上取得了进展,但存在明显局限:它们通常严重依赖专家知识进行特征工程和分子参数化,需要高通量实验平台提供大量数据,并且大多只能在专家预先设定的“封闭反应空间”(如一个固定的配体或溶剂库)内进行优化,这可能导致错过性能更优的未知选择。
近年来,以GPT为代表的大语言模型展现了强大的通用能力,但在化学领域的应用仍处于初级阶段,其化学专业能力有限,难以自主探索和优化未报道的反应。为了克服上述挑战,研究者们提出了一个核心问题:我们能否构建一个深度融合化学知识的大语言模型,它既能像人类化学家一样从SMILES分子式和反应数据中理解化学结构和规律,又具备LLM的强大生成能力,从而能够在开放的反应空间中进行真正的探索与发现?因此,该研究设计提出白玉兰化学合成大模型(称之为Chemma),旨在成为能够与化学家互动、辅助实验决策、并最终加速有机合成进程的生成式AI助手。Chemma 能从SMILES序列中学习分子表征,理解化学结构;通过海量反应数据预训练,Chemma能像化学家一样学习反应物、产物和条件之间的复杂关系;Chemma的生成能力使其能够设计全新的分子(如推荐新配体),从而突破预设条件的限制,指导探索新反应(下图所示)。
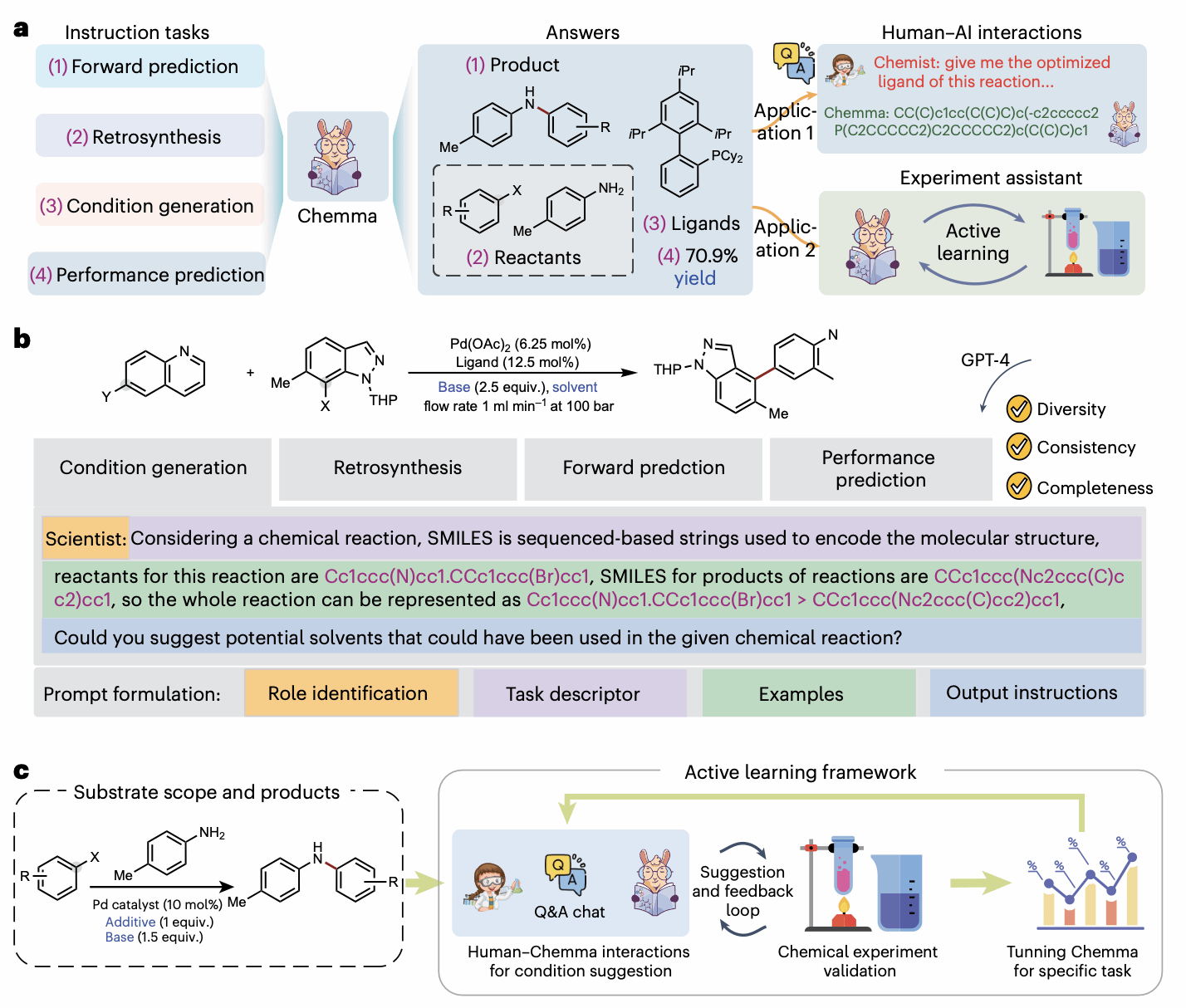
图1: Chemma协助有机化学合成的功能与应用场景。科学家可以围绕四项主要任务与Chemma交流,包括正向反应预测、逆合成、条件生成和性能预测(如产率和选择性)。
创新成果:
团队实现在多个化学基准任务上性能验证。在USPTO-50k数据集上,Chemma在单步逆合成任务中实现了72.2%的Top-1准确率,显著优于文献报道的最优Top-1准确率57.7%。在多步合成测试中,Chemma能够设计合理的反应步骤,并通过专家验证;对于产率预测/选择性预测(区域选择性与对映选择性)任务,Chemma无需DFT特征,对高通量实验数据预测R2达到了0.88;对于配体/催化剂推荐任务,Chemma可在预设条件下给出最优配体,在多数测试组合中,其推荐配体带来更高中位产率,同时准确率达到93.7%。依托变革性分子前沿科学中心, 针对特定反应,Chemma可在线设计生成20多种催化剂,10多种试剂,和多种添加剂,同时实现实验优化,快速提高化学实验效率。
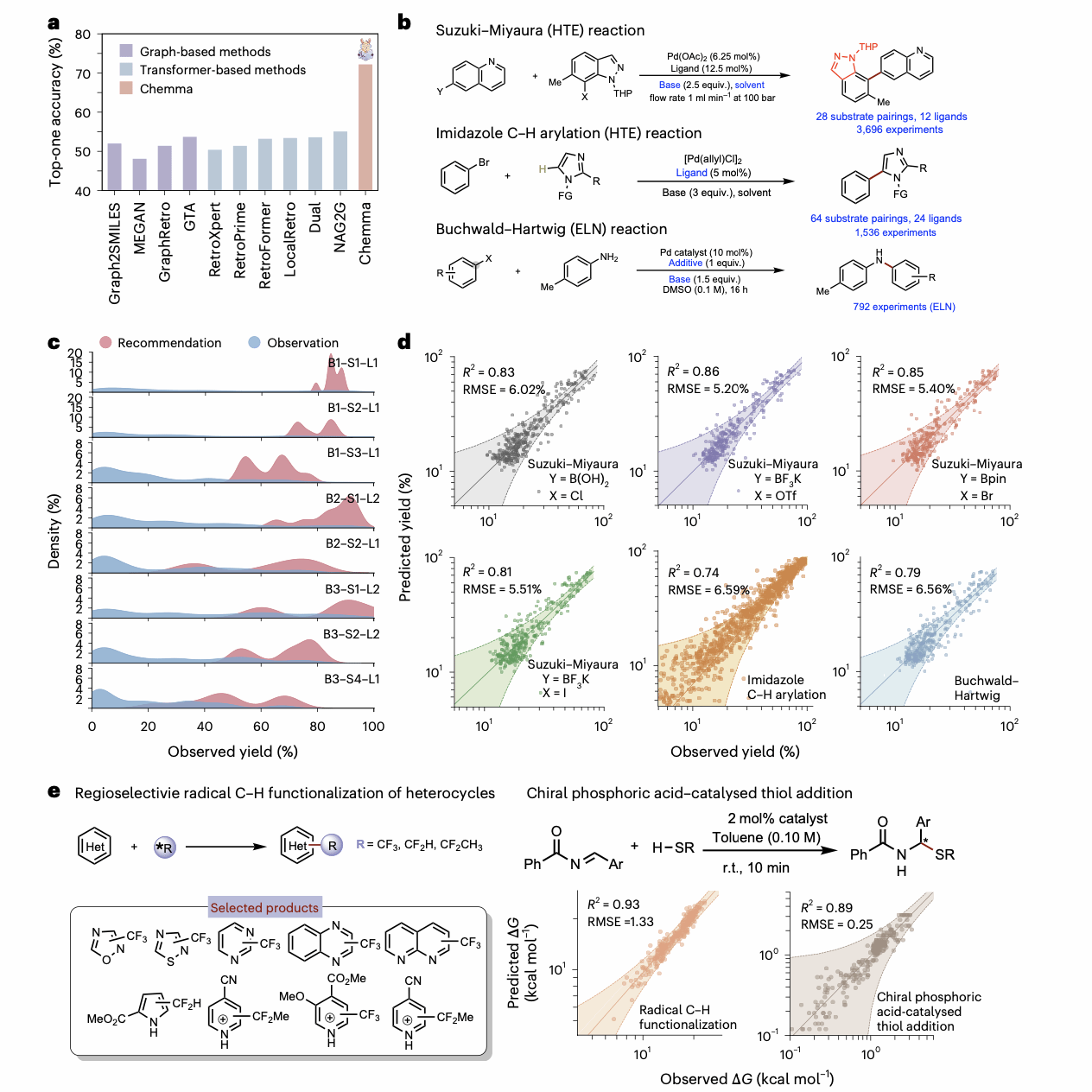
图 2: Chemma在不同有机合成任务上的性能评估,包括正向反应预测、逆合成、条件生成和性能预测(如产率和选择性)。
除了预测能力之外,Chemma还可作为“数据生成器”,在数据稀疏的情况下,通过生成高质量伪数据来提升传统实验优化算法(BO)的性能。实验验证在Suzuki–Miyaura与Buchwald–Hartwig反应中大幅减少了实验次数,相比传统BO算法需要50次以上,Chemma-BO仅用10-15次实验就能达到98%以上的产率,反应优化效率提高50%。
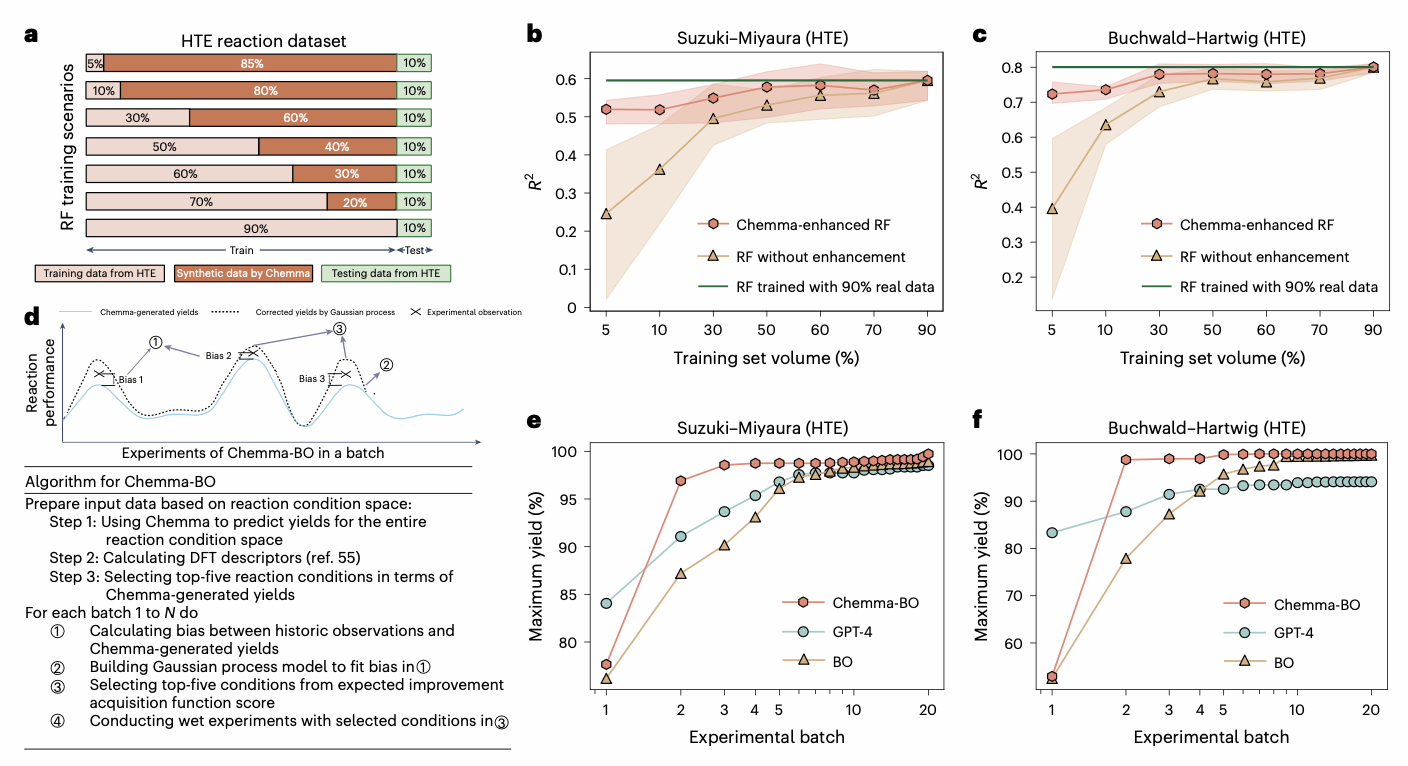
图 3: Chemma合成数据用于提高产率预测和反应优化,评估三种不同方法(Chemma-BO、GPT-4和BO)在铃木-宫浦和布赫瓦尔德-哈特维希反应上的平均累计最大观察产率。
该模型不能能够实现反应预测,还能从未知反应空间中探索实现反应设计和优化。在变革性分子前沿科学中心朱峰副教授的大力支持下,团队开展了湿实验验证。对于一个未报道N杂环交叉偶联反应,研究人员将Chemma集成入主动学习框架,探索反应适配的配体与溶剂。通过“人-机协作”的主动学习循环,第一轮尝试失败后,Chemma进行实验数据反馈和在线微调,在第二轮便精准地推荐了高效的配体(PAd3),最终仅用15次实验,就成功实现了67%的分离产率。此任务展示了Chemma在开放反应空间中辅助探索未知反应条件的潜力。
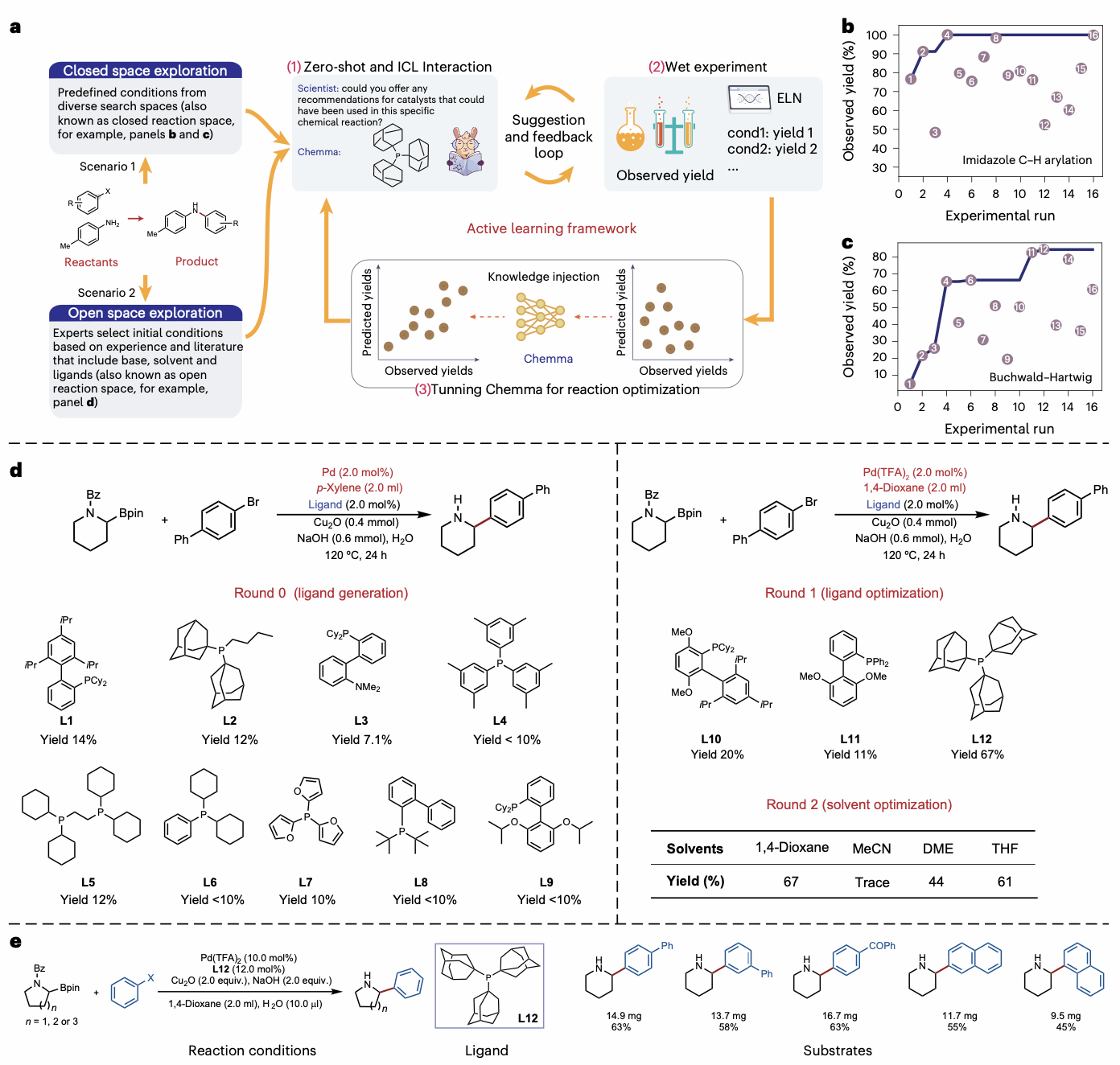
图 4:Chemma驱动的反应探索和优化的主动学习框架。通过主动学习框架对未见文献报道的反应(α-芳基 N 杂环的合成)进行配体和溶剂的探索。
研究意义:
研究团队另辟蹊径,将化学反应视作自然语言任务,学习其结构与规律,在多个有机化学任务中表现优异,展现出良好的人机协作能力。特别是在无需DFT的条件下实现产率与选择性的精准预测,以及在开放空间中完成自主优化,充分证明了语言模型在化学合成中的适用性。
作者信息
上海交通大学人工智能研究院博士生张雨为本文第一作者,变革性分子前沿科学中心博士生韩阳和陈帅在湿实验方面做出重要贡献。人工智能研究院许岩岩副教授、金耀辉教授、杨小康教授、上海交通大学变革性分子前沿科学中心朱峰副教授为本文通讯作者。丁奎岭院士对本研究给予了宝贵的建议和指导,本研究得到了上海市人工智能重大专项资助,以及上海交通大学AI for Science科学数据开源开放平台支持。




